Reverse Image Search with Machine Learning
How can we extract actionable meaning from image data?
Demo app from commercetools using the Image Search API.
The Machine Learning team at commercetools is excited to release the beta version of our new Image Search API.
Image search (sometimes called reverse image search) is a tool, where given an image as a query, a duplicate or similar image is returned as a response. The technology driving this search engine is called computer vision, and advancements in this field are giving way to some compelling product features.
What is an image?
To build an image search system, we first need a way to find meaning from image data. To a computer, an image is a 3-D matrix consisting of hundreds of thousands of numbers, representing red-green-blue (RGB) pixel values. But to a human, an image is an arrangement of semantic patterns — lines, curves, gradients, textures, colors — all of which integrate into some meaningful idea.
Figure 1: Zoomed in view of RGB pixels of a computer screen.
Convolutional Neural Networks: the forefront of machine vision
A relatively new computer vision model, called a Convolutional Neural Network (CNN), can be used to bridge this gap between man and machine — the CNN extracts latent meaning from images.
The most powerful advantage of using a CNN over other machine learning techniques is that it models the fact that nearby pixels are often locally correlated with one another (if one pixel in an image is part of a cute dog, odds are the surrounding pixels are as well). Albeit a simple idea, this is an incredibly powerful algorithm in practice, since previous image recognition technologies were constrained by detecting only color or very low level shapes for features. The CNN decides which features are important automatically in its training process, where it learns what is statistically significant vs. irrelevant from millions of example images.
CNNs are so powerful that some form of them have been the winning algorithm of the the largest image recognition contest in the world, ImageNet, every year since 2012. You will find CNNs as the eyes behind self-driving cars, facial recognition on your phone, cancer detection software from CT scans, and even in Google Deep Mind’s Alpha Go.
How a CNN works
A CNN is a series of layers, where each layer is a function which takes the output of the previous layer as an input. An image is input into the first layer, and each time it passes through a new layer, the most meaningful features are extracted and passed forward. After each layer, the semantic representation of the new image becomes more dense. Generally, the first layers of the network extract low level features, like edges, and later levels combine these features into more abstract, and often meaningful shapes or ideas — like that wheels always go at the bottom of a car.
Figure 2, below, shows that the first layers identify sharp edges in the image, the middle layers combine these shapes into wheels and the car body, and the final layer makes a coherent assertion that this is an image of a car. In practice, a CNN may have dozens of layers.
Figure 2: What a CNN sees. Source: “Unsupervised Learning of Hierarchical Representations with Convolutional Deep Belief Networks” ICML 2009 & Comm. ACM 2011. Honglak Lee, Roger Grosse, Rajesh Ranganath, and Andrew Ng.
Each layer of the network applies a filter to the input, and what these filters do to the image is part of the alchemy of deep learning. Each filter is a set of unique weights, and those weights are multiplied by the pixel values within a small window of the input image, generating the new image (this process is called a convolution). The new image is “deeper” in the z-dimension (as opposed to the length and width), and this depth encapsulates learned features.
Was it Einstein who said, “If you can’t explain it simply, use a GIF.”?
Figure 3 below shows the application of a filter to the input, the blue image, compacting it into the green image. A 3x3 window of the input is multiplied by the filter weights, and a single value is output. So the information within a 5x5 image gets mapped to a more dense 2x2 version.
Additionally, the resulting condensed image is sub-sampled with another filter which simply finds the maximum or average value in the window, to further reduce its size. The final layer is collapsed into a single dimensional vector, an array of numbers, representing the features extracted from the image. This feature vector is the basis for our similar image search. And voila, we have a basic CNN!
Figure 4: Basic CNN diagram.
The values of the weights in the filters are determined during the model training process, where thousands, or even millions of images are passed through the network. Each image has a label of what is in it, like “cat” or “dog”. Every time an image is passed through the network, its feature vector is mapped to the labels, and a probability score is generated. The CNN might say “there is a 75% chance this is a dog, and a 25% chance this is a cat.”.
With each pass, a calculation is made about which direction we can push the weights of the filters to generate a more accurate probability score — we want the model to be more confident in its assertions. Once we’re satisfied with the score (usually when it stops improving, after several thousand passes), we end the training process, and use the model only for predictions on new, unseen images.
Comparing feature vectors
So far we’ve trained the network to see images the same way we see as relevant. But we still need a mechanism for the computer to compare the extracted feature vectors for similarity.
If you or I were to decide if two images are similar, our brains would probably determine how similar certain features are within each image. If two images both contained furry, four-legged animals, we would be more likely to pair those together, relative to a third image of a smooth, two-legged reptilian animal. Similarly, for the CNN model, we compare resulting feature vectors against each other by measuring the distance between their vectors. Image feature vectors with small distance scores suggest their underlying image contain similar contents.
If two images both contained furry, four-legged animals, we would be more likely to pair those together, relative to a third image of a smooth, two-legged reptilian animal.
Figure 4: Image similarity.
Measuring distance
Euclidian distance (the length of a line between two points), although simple, fails as a good metric in this context. One reason for this is that for our feature vectors, it is better to measure the correlation between features, rather than the features themselves. The cosine distance does this by measuring the angle between two vectors.
We can expect a feature vector to between between 100 and 4000 dimensions, so lets simplify things to the 2D world. Figure 5 below illustrates the distinction between euclidean vs. cosine distance.
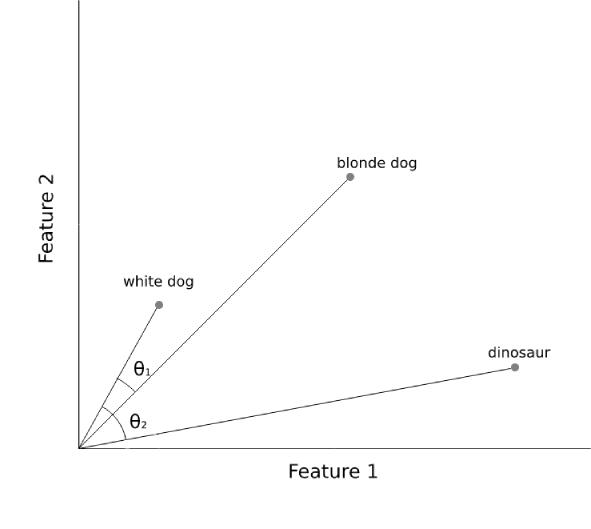
Figure 5: Cosine distance. θ1 has a smaller angle than θ2, denoting more similar feature vectors.
The dog vectors point in similar directions, meaning their two features vary together more, relative to the dinosaur vector (angle θ1 is smaller than θ2). Despite this, the linear distance between the blonde dog and the other two animals is still roughly equal. Rather than identifying vectors with values which are of similar magnitude (Euclidian), in image search we prefer finding vectors with the most similar patterns (cosine).
Great, we have a way to generate feature vectors from images and compare their similarity, but how do we serve this application to users, and scale?
From feature vector to image search
As is the case with all production machine learning projects, the next step is to build software engineering infrastructure around our predictive model. In practice, this is a matter of vectorizing hundreds of thousands of product images, indexing those feature vectors into a relational database, and serving it as an API.
Figure 6: UML Diagram of image search pipeline
To index a customer’s project’s images, we first run an asynchronous Python celery process for them. This process iterates through all unique images within all of the project’s product variants and creates a reference for it’s unique product and URL information.
We vectorize each unique image URL using a CNN model created with Python’s deep learning library, Keras. The model is hosted on Google ML Engine to achieve rapid and responsive scaling for handling changes in demand. After evaluating image retrieval performance of several CNN models, our team decided to use a pretrained VGG16 network, which achieves 92.7% accuracy on ImageNet, a dataset of over 14 million images belonging to 1000 labels. As we aggregate feedback, we plan to improve our model using more e-commerce specific data.
To allow for efficient storage and access of a large and growing amount of image data, we used a PostgreSQL database. We store each feature vector and its URL/product reference in two separate tables, since there can be a many-to-many mapping of products to images.
A great feature about SQL is the ability to perform basic arithmetic within a query. Since cosine distance in this context is a linear combination of column values, we perform that operation within a SELECT query when comparing all image feature vectors to a new input image vector. This allows us to only return the closest vectors from the database as a response, reducing I/O bound latency.
Once a customer’s project is indexed, he or she sends an image as an HTTP request (see docs for an example request) to us, the image is vectorized and queried against our database for similar images, and the top results are returned as image URLs in a JSON response.
Putting image search to use
At this point, we are bound by our own creativity. The similar image response object could be used by a shop owner to make a more convenient app, where a customer could snap a photo of a product they like, and see if the shop carries something similar. He or she could also check for duplicate images in their database, or to verify if someone else is stealing images from them.
Figure 7: Demo app from commercetools using the Image Search API.
From product recommendations to image authentication and more, our new Image Search API opens a host of new opportunities to explore, and we’re excited to see how our customers put the tool into practice!
View original content here
Related commercetools News: